TL;DR
Three papers with Plastic Labs authors were accepted at ICLR 2026. One learns to control how a frozen LLM samples at test time. One gives you a window into what a model is actually uncertain about during generation. One trains reasoning capabilities from scratch using nothing but competitive self-play. We'll be in Brazil for the conference, so come by and chat with us!
Both Yuya and Vince will be in Rio - sign up here to get in touch!
We are at ICLR!
Research is core to what we do at Plastic Labs. The thesis behind Honcho that memory should be a reasoning task requires deep research which can unlock genuinely new behavior from language models.
This requires us to stay close to the frontier. So it's gratifying that this year, three papers with Plastic Labs authors landed at ICLR 2026. They span different corners of the LLM stack from decoding, uncertainty, and emergent reasoning. But they all share a common thread: the most interesting improvements to language models don't always require touching the weights.
Here's what we've been working on.
Adaptive Decoding via Test-Time Policy Learning
Workshop: AI with Recursive Self-Improvement @ ICLR 2026
ArXiv Paper: arxiv.org/abs/2603.18428
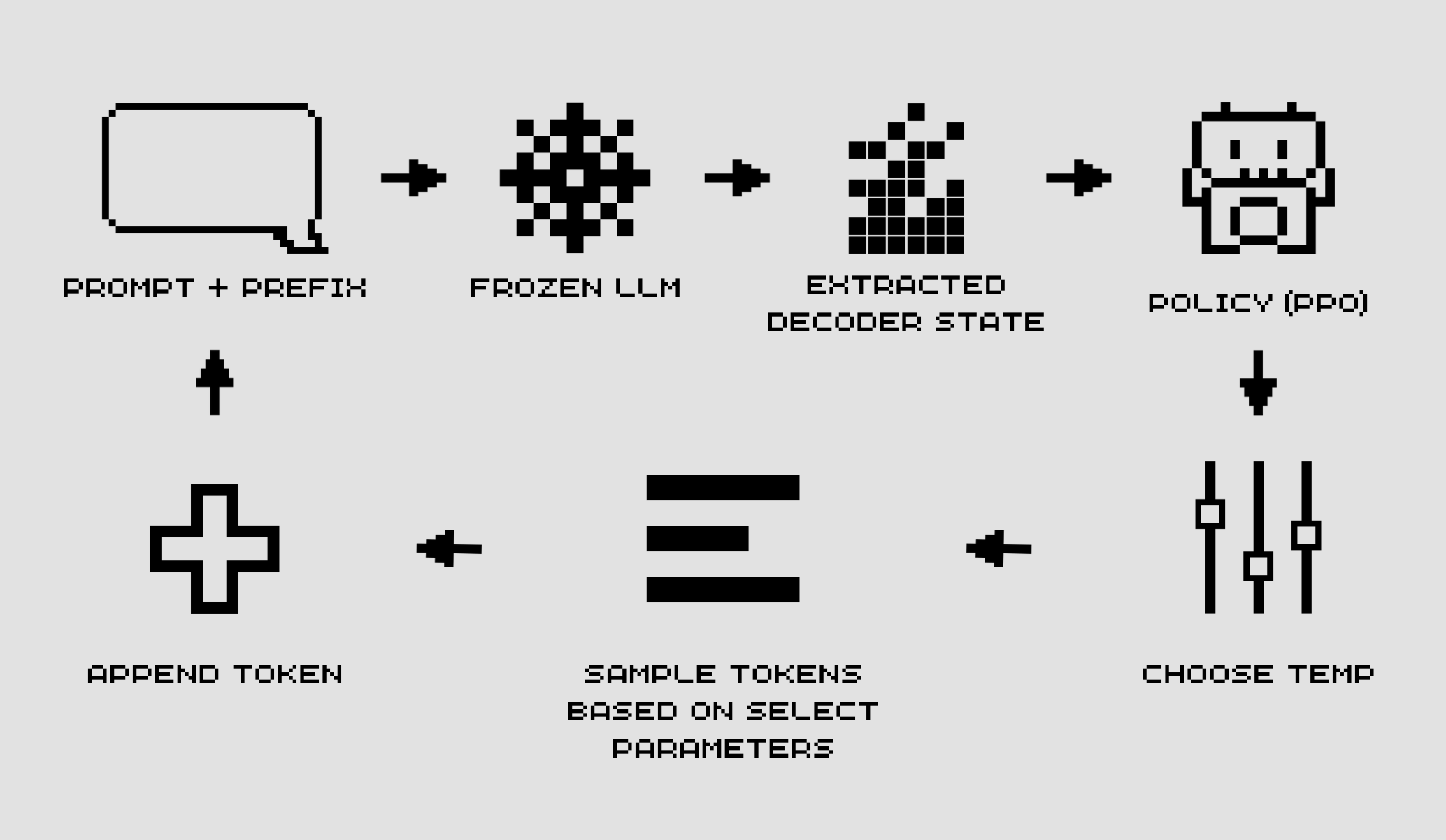 Figure 1: Overview of the RL-based decoder sampler. The agent observes the decoding state from a
frozen LLM, selects decoding parameters (e.g., temperature and top-p), and receives rewards guiding
adaptive sampling.
Figure 1: Overview of the RL-based decoder sampler. The agent observes the decoding state from a
frozen LLM, selects decoding parameters (e.g., temperature and top-p), and receives rewards guiding
adaptive sampling.
Static decoding is a quiet bottleneck. Greedy, top-p, temperature…, these are fixed heuristics chosen before generation starts and held constant throughout. They don't adapt to the evolving context of what's being generated. They don't know whether the current step is stylistically unconstrained or syntactically forced. They just apply the same rules uniformly, everywhere.
This paper asks a direct question: what if a lightweight agent could watch a frozen LLM generate and dynamically adjust its sampling parameters at each step?
We frame decoding as a Markov Decision Process. The agent observes the current generation state, which includes the prompt, the prefix, the model logits, the entropy of the next-token distribution and selects a temperature and top-p value to use for that step. A PPO-trained policy learns to make those decisions. The LLM itself never changes.
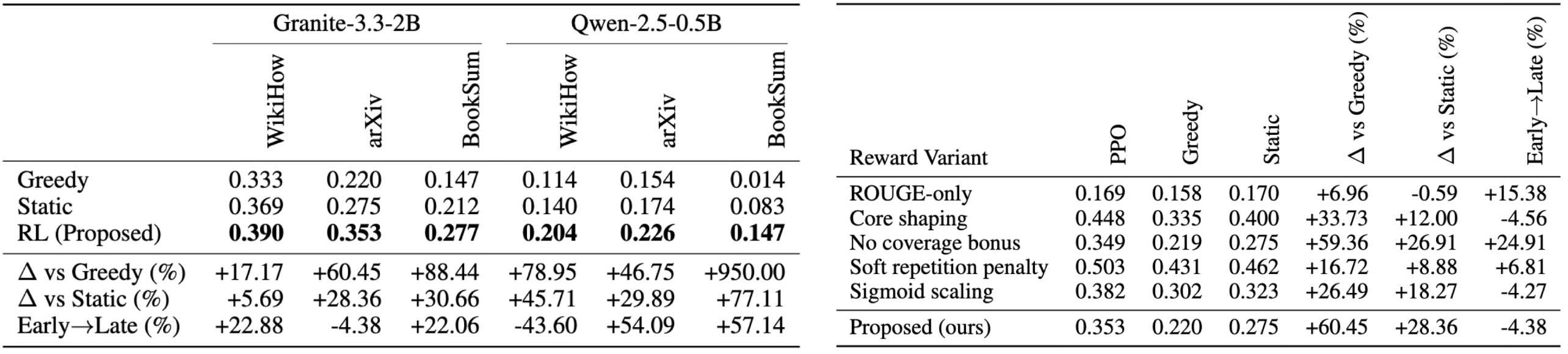 Figure 2: (Left) Main evaluation results with the Proposed Reward. RL achieves consistent improvements over greedy and static baselines. Scores are reported alongside percentage gains and PPO early → late improvements. (Right) Reward ablations on arXiv (Granite-3.3-2B). We report absolute rewards, percentage improvements over baselines, and PPO early → late change.
Figure 2: (Left) Main evaluation results with the Proposed Reward. RL achieves consistent improvements over greedy and static baselines. Scores are reported alongside percentage gains and PPO early → late improvements. (Right) Reward ablations on arXiv (Granite-3.3-2B). We report absolute rewards, percentage improvements over baselines, and PPO early → late change.
The results hold up across models and domains. On summarization benchmarks using Granite-3.3-2B and Qwen-2.5-0.5B, the RL-trained decoder consistently outperforms greedy and static baselines. The gains are largest on tasks with high stylistic variability including BookSum and WikiHow, exactly where static heuristics are most brittle. Relative improvements reach +88% on BookSum with Granite and +79% on WikiHow with Qwen.
Two findings stand out from the ablations. First, reward design matters as much as the RL algorithm itself. ROUGE-only rewards yield negligible gains; structured shaping terms such as length, coverage, repetition, completeness are what produce stable learning. Second, even small models benefit significantly from adaptive decoding, which matters in resource-constrained deployments where fine-tuning isn't viable.
The policy is a 2-layer MLP. Per-token compute overhead is negligible. It's decoupled entirely from the base model, and it can be rolled back by simply disabling it. That reversibility matters when you're deploying something at the inference layer rather than baking it into the weights. Decoding is an underexplored intervention point. This paper is an early step toward making it learnable.
LogitScope: Analyzing LLM Uncertainty Through Information Metrics
Workshop: Catch, Adapt, and Operate: Monitoring ML Models Under Drift Workshop @ ICLR 2026
ArXiv Paper: arxiv.org/abs/2603.24929
Most approaches to understanding what an LLM is uncertain about require either multiple forward passes or an external verification model. Both introduce overhead. Neither gives you direct access to the distribution-level behavior happening at each generation step.
LogitScope takes a different approach. At every token position, a language model produces a full probability distribution over its vocabulary. That distribution contains a lot of information and most of it gets discarded. LogitScope captures it.
The framework computes six metrics from the token probability distribution:
| Metric | Description |
|---|---|
| Entropy | Overall uncertainty across possible tokens |
| Varentropy | Variance of surprisal values, revealing multimodal distributions where the model is genuinely torn between distinct alternatives |
| Surprisal | How unexpected the actually selected token was |
| Skewentropy | Asymmetry of the distribution space |
| Probability | Direct confidence on the chosen token |
| Perplexity | Cumulative sequence-level quality measure |
The entropy/varentropy pair is particularly diagnostic. Low entropy and low varentropy means the model is confident as one token dominates. High entropy and high varentropy means the model sees multiple plausible paths of roughly equal weight. That's a meaningful signal. It often appears at semantic decision points, and it correlates with hallucination-prone regions.
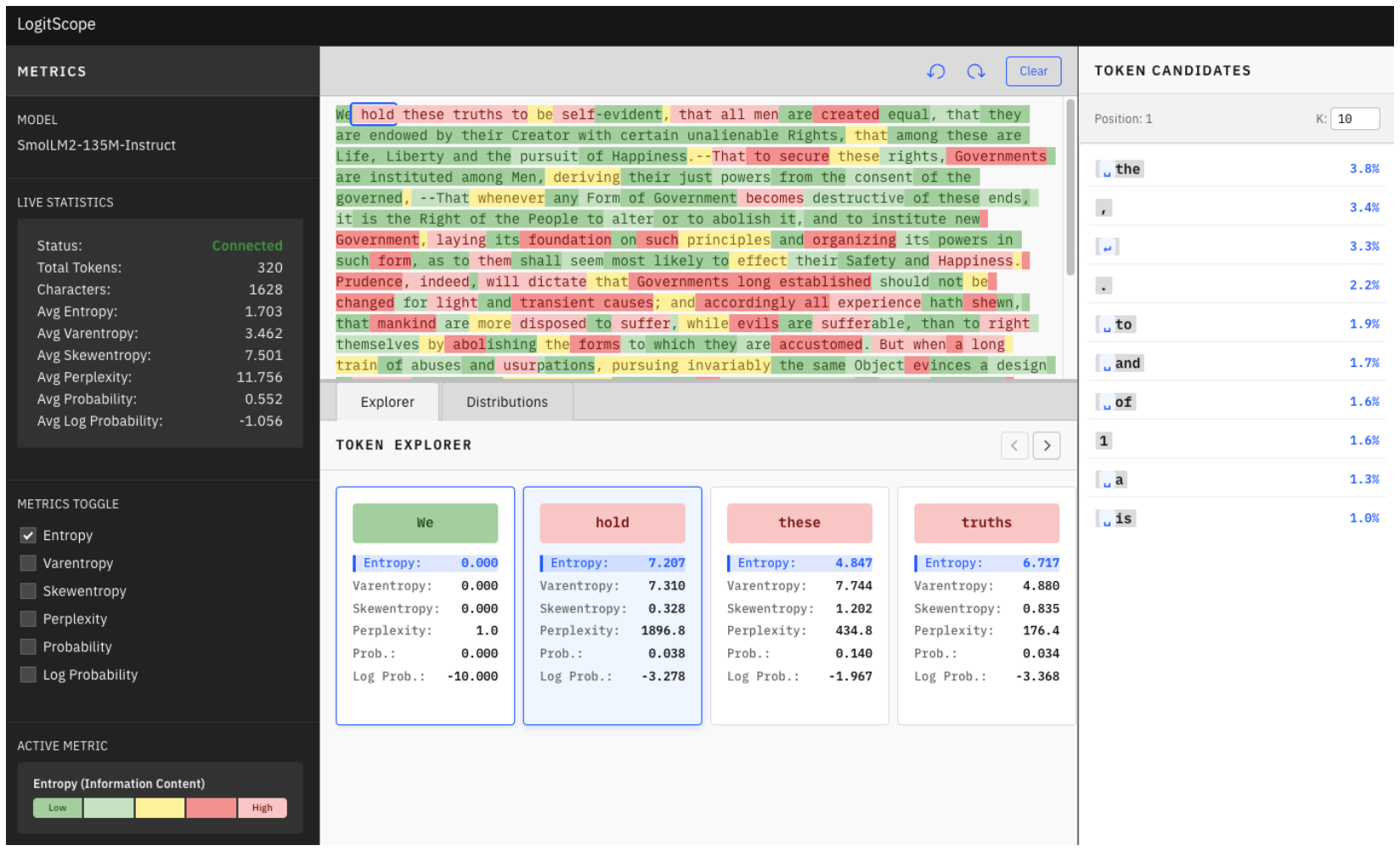 Figure 3: The web interface displaying the entropy metric. Tokens are color-coded by magnitude, with brighter colors indicating higher uncertainty. The sidebar shows aggregate statistics for quick assessment of overall model confidence.
Figure 3: The web interface displaying the entropy metric. Tokens are color-coded by magnitude, with brighter colors indicating higher uncertainty. The sidebar shows aggregate statistics for quick assessment of overall model confidence.
The tool is a lightweight wrapper around HuggingFace Transformers. It uses lazy evaluation so metrics are computed on demand. It exposes raw logits and distributions for custom analysis without copying data. It works on CPU, CUDA, and Apple Silicon. It requires no labeled data, no additional model calls, and no semantic interpretation.
The applications are broad: hallucination detection, prompt engineering, model comparison, production monitoring. If your aggregate entropy distribution suddenly shifts, something has changed. You'll know before you have ground truth labels to confirm it.
SPIRAL: Self-Play on Zero-Sum Games Incentivizes Reasoning
Conference Paper: ICLR 2026
ArXiv Paper: arxiv.org/abs/2506.24119
 Source: Liu, Guertler et al., 2025.
Source: Liu, Guertler et al., 2025.
The most expensive part of standard reasoning training is the human annotation. Every problem needs to be curated, every answer verified, every reward function engineered for the target domain. That process doesn't scale. It limits how broadly and quickly we can develop new reasoning capabilities. SPIRAL removes that bottleneck entirely.
The idea is simple: put two instances of the same model against each other in a zero-sum language game. The model that wins gets a positive reward. The model that loses gets a negative one. No humans, no curated problem sets, no domain-specific reward engineering. The game outcome is the supervision signal. The implementation is less simple. Multi-turn, multi-agent autoregressive generation across a shared policy creates genuine training instabilities. Standard REINFORCE in this setting suffers from high variance — the opponent's strategy is continuously evolving, so the environment is non-stationary from any individual model's perspective.
SPIRAL addresses this with Role-conditioned Advantage Estimation (RAE). The key insight is that in a two-player game, even with a shared policy, different roles have different expected returns. For example, the first-move advantage in TicTacToe and information asymmetry in Kuhn Poker. RAE maintains separate baselines for each game and each role, updating them via exponential moving average. Advantages are computed relative to role-specific expectations. This simple modification prevents what the paper calls "thinking collapse" which is a failure mode where, without proper variance reduction, models progressively abandon reasoning traces and degenerate to near-empty outputs within 200 training steps. The games used in training are TicTacToe, Kuhn Poker, and Simple Negotiation. Each develops a distinct cognitive profile: spatial reasoning, probabilistic inference, and multi-constraint optimization. These capabilities transfer. Multi-game SPIRAL training improves reasoning benchmark performance by up to 10.5% across MATH500, OlympiadBench, AIME, GPQA, and MMLU-Pro without any exposure to benchmark-related problems during training.
Critically, that transfer exceeds supervised fine-tuning on 25,000 expert game trajectories generated by a Qwen3-32B model. Self-play discovers more effective reasoning strategies than imitating experts. Fixed opponents, by contrast, plateau once exploitable strategies are found. Self-play's automatic curriculum, where the model always faces a version of itself, is what drives continuous improvement. The reasoning patterns that transfer are concrete: case-by-case analysis, expected value calculation, pattern recognition. Case-by-case analysis in particular transfers near-perfectly from games to mathematics (72% to 71%). The paper tracks these patterns across checkpoints and finds that they develop via gameplay and migrate into mathematical reasoning as training progresses.
More details on this research can be found in this blog post.
The code is at github.com/spiral-rl/spiral.
A Thread Running Through All Three
These papers solve different problems. But they share an orientation: language model behavior can be significantly improved at the post-training and inference layer, without touching the underlying pretrained weights and often without human-curated supervision at all.
The decoder sampler learns to control generation without retraining the LLM. LogitScope extracts uncertainty signals already present in the forward pass, no additional models required. SPIRAL builds reasoning from competitive dynamics alone, no problem sets needed.
That orientation matters to us because it maps directly onto the theses we hold at Plastic Labs. Honcho's memory-as-reasoning thesis is fundamentally about what becomes possible when you stop treating language models as static artifacts and start treating inference as a site of active learning and adaptation. We're still early. But these papers are evidence that the direction is right.
Find Us in Brazil
We'll be at ICLR in Brazil! If you're working on inference-time learning, post-training methods, uncertainty in language models, or memory and personalization for agents, we want to talk!
Both Yuya (@3un01a) and Vince (@vintrotweets) will be at the conference.
If you would like to get in touch, please fill out this Typeform.