TL;DR
Honcho achieves state-of-the-art performance across the LongMem, LoCoMo, and BEAM memory benchmarks--90.4% on LongMem S (92.6% with Gemini 3 Pro), 89.9% on LoCoMo (beating our previous score of 86.9%), and top scores across all BEAM tests. We do so while maintaining SOTA token efficiency.
But testing recall on benchmark data that fits in frontier context windows is no longer particularly meaningful. Beyond simple recall, Honcho reasons over memory and empowers frontier models to reason across more tokens than their context windows support.
Check out evals.honcho.dev for charts and comparisons.
1. A Primer on Honcho's Architecture
Read Honcho's documentation for a full understanding of how Honcho works, but a brief overview is important for understanding our benchmarking methodology and how Honcho achieves state-of-the-art results:
- Honcho is a 'memory agent': it runs as a server which ingests messages, reasons, & exposes a variety of query endpoints
- When a message or batch of messages is stored in Honcho, it uses small fine-tuned models to capture all latent information & save it as a 'Representation' of the author1
- In the background, Honcho regularly 'dreams'2 across ingested messages & prior reasoning to make deductions & reach further conclusions
- Honcho's API exposes a chat endpoint containing a research agent that uses a powerful model to call tools & get the best possible answer to any natural language query.
For the sake of reproducibility, all benchmark results published here were generated using gemini-2.5-flash-lite as the ingestion model and *claude-haiku-4-5 as the chat endpoint model. In practice, Honcho uses a variety of models for these roles as well as for dreaming processes.
We also tune Honcho for various use cases. For example, the message batch size when ingesting messages and the amount of tokens spent on dreaming both have an effect on performance. Notes on the configuration for each benchmark are included, and the full configuration for each run is included in the data.
2. Memory Benchmarks
Here we evaluate Honcho's preformance on three different benchmarks: LongMem, LoCoMo, and BEAM.
LongMem
LongMem S is a data set containing 500 "needle-in-a-haystack" questions, each with about 550 messages distributed over 50 sessions, totaling ~115,000 tokens of context per question.
After ingesting this context, a single query is made and judged. The correct answer hinges on information divulged in one or a handful of messages: these are the "needles." Everything else is "hay." The questions come in six flavors:
- single-session-user
- single-session-assistant
- single-session-preference
- multi-session
- temporal-reasoning
- knowledge-update
Answers are canonically judged using GPT-4o with a prompt defined in the LongMem paper.3 The prompt varies based on the question type.
Notably, LongMem does not test a memory system's ability to recall across truly large quantities of data: each question's message history fits comfortably within the context window of most modern LLMs. LongMem was originally designed, and still serves, to highlight an important phenomenon in LLM context windows: just because some information is within the context window does not mean a model can productively recall it.
Running LongMem with Claude Haiku 4.5 without any augmentation--merely dropping the full conversation preceding a question into the context window, then asking the question--yields a score of 62.6%. Rather than comparing this to a theoretical score of 100%, though, this score should be compared to the same model run against LongMem Oracle: The same questions as the 'S' data set, but with only the one-to-three sessions containing the needle(s). Claude Haiku 4.5 scores 89.2%. So, adding 115,000 tokens of 'hay' leads to a 26.6% drop-off in performance. This behavior is fairly consistent across models, with smaller models generally displaying even larger drop-off and the highest-tier of frontier models holding up slightly better.
Another key fact about LongMem revealed by the Oracle variant is that there's a component of reasoning, not just recall. Failures on Oracle questions mean that the model simply isn't smart enough to generate the correct answer.4 We can therefore treat the Oracle score for a given model as a (very) rough indicator of the ceiling at which that model can operate within a memory framework.
With Claude Haiku 4.5 as the chat endpoint model, Honcho scores 90.4% on LongMem S and 91.8% on LongMem Oracle. Almost no drop-off in recall. In fact, Honcho empowers the model running inside to perform better with fewer tokens: the chat endpoint uses a median 5%, mean 11% of the question's context to answer correctly 90.4% of the time--that's better than the same model on the minimized data set containing only the answers!
Token efficiency at this level allows us to use more expensive models on the chat endpoint, leading to higher quality reasoning over the total latent information extracted from content ingested by Honcho. (More on this in section 3.)
Full results:
| Category | Passed | Total | Success Rate |
|---|---|---|---|
| Single-Session Assistant | 54 | 56 | 96.4% |
| Knowledge Update | 74 | 78 | 94.9% |
| Single-Session User | 66 | 70 | 94.3% |
| Single-Session Preference | 27 | 30 | 90.0% |
| Temporal Reasoning | 118 | 133 | 88.7% |
| Multi-Session | 113 | 133 | 85.0% |
Configuration: 16,384 tokens per message batch, dreaming OFF. Full data.
LongMem M
LongMem M is the big brother to S. Each question has roughly 500 sessions, equivalent to over 1M tokens.
We asked Honcho 98 questions from LongMem M, and scored 88.8% using the same configuration that we used for S. That's a less than 2% drop-off when injecting about a million extra tokens of "hay" into the source material: real evidence that Honcho is effectively expanding the ability of a model to reason over tokens beyond context window limits.
But just adding extra noise to a conversation history isn't really getting at what we think of when we use the word "memory." Eliminating irrelevant data mostly comes down to optimizing RAG strategy and designing good search tools for an agent. True memory involves processing everything, even the "irrelevant" data, and using it to form a mental model of the author. The retrieval questions in LongMem don't get more nuanced with more data, and Honcho can easily eliminate noise to find the answer while doing much more behind the scenes.
A Note on Model Selection
LongMem has been fashionable over the past year as a benchmark for anyone releasing an agent memory system. It's important to remember that when the benchmark was first released, GPT-4o scored 60.6% on LongMem S without augmentation. It was a clear demonstration that token-space memory augmentation had a place even in the scale of 100,000 tokens or less, even before questions of cost-efficiency.
After over a year, this is no longer the case. Gemini 3 Pro can run LongMem S, easily fitting the per-question ~115K tokens into its context window, and score 92.0%. By itself. This score is higher than any published LongMem score by a memory framework project, including two that actually used Gemini 3 Pro as their response-generating model for the eval. Their systems are degrading the latent capability of the model.5
Honcho with Gemini 3 Pro scores 92.6%. We're not impressed by that marginal improvement, though it's good to know we're not actively impeding the model. All these results reveal is that from here on out, memory frameworks cannot merely announce scores on low-token-count tests. There are two ways to prove a memory framework is useful:
-
Demonstrate recall over more tokens than fit in the context window of top-tier models today: one million or more.
-
Demonstrate cost efficiency: calculate the cost of ingesting a certain number of tokens with a top-tier model to produce a correct answer, then get the same answer by spending less money on input tokens using a memory tool.
Honcho passes both of these tests.
Running LongMem S directly with Gemini 3 Pro costs about $115 for input tokens alone (the relevant part for retrieval–output tokens don't really change). Honcho with the same model had a mean token efficiency of 16%--bringing ingestion cost down to $18.40. Adding the cost of running Honcho's ingestion system with Gemini 2.5 flash-lite, a model quite effective for the task, brings total cost up to $47.15--a 60% cost reduction. The Honcho managed service does not charge for ingestion--we operate our own fine-tuned models for the task. (For more discussion of cost efficiency, see section 3.)
LoCoMo
We assert that LongMem doesn't "test a memory system's ability to recall across truly large quantities of data": this is even more true for LoCoMo. It takes a similar format to LongMem, but instead of 115,000 tokens per question, it provides a meager 16,000 tokens on average of context. Then, each of these 16k token conversations has a battery of 100 or more questions applied to them.
Given that contemporary models routinely offer a context window of 200,000 tokens or more, a 16,000 token conversation really isn't useful at all in evaluating a memory framework.
Even still, Honcho achieves better performance on the test than a model acting alone. We score 89.9% on the full LoCoMo benchmark. Haiku alone scores 83.9%.6 For reference, that means Honcho answers about 100 questions that the model acting alone cannot. Improvement is spread fairly evenly across all question categories, which makes sense given the small context size (the model isn't really experiencing 'forgetfulness' due to context overload) and our dreaming methodology that reasons over the data in the background before any questions are asked.
| Category | Passed | Total | Success Rate |
|---|---|---|---|
| Commonsense | 784 | 841 | 93.2% |
| Multi-Hop | 283 | 321 | 88.2% |
| Single-Hop | 237 | 282 | 84.0% |
| Temporal | 74 | 96 | 77.1% |
Configuration: 128 tokens per message batch (1-5 messages per batch, in practice), dreaming ON. Full data.
BEAM
At this point, you might be wondering if any so-called memory benchmarks can meaningfully evaluate a memory solution?
BEAM, "BEyond A Million" Tokens, is your answer.
BEAM comes in four flavors: 100K, 500K, 1M, and 10M. Those stand, loosely, for the number of tokens provided as context for the evaluation's questions. Released in October 2025, BEAM introduces a high-quality set of conversations and questions spanning up to ten million tokens. The paper also introduces a memory framework of its own, noting an improvement of 3-12% over baseline. Like the previous benchmarks, BEAM measures the phenomenon of LLMs exhibiting forgetfulness as the context window fills up. We believe it also uniquely judges the ability of a memory framework to empower LLMs to reason beyond the context window.
BEAM's judge is thoroughly defined, including a rubric, tool calls, and detailed prompts for multiple question types. Many of BEAM's question categories look familiar: temporal reasoning, multi-session reasoning, knowledge update, abstention, and preference following. It also introduces some new categories not tested in the other benchmarks: contradiction resolution, event ordering, information extraction, instruction following, and summarization.
BEAM scoring is different from LongMem and LoCoMo: rather than setting a pass/fail criterion and scoring the overall test by pass rate, BEAM's judge grades each question individually, and the overall test grade is the average of these scores. The LLM judge is instructed to, and naturally leans towards, grading in a step-function pattern: each question's rubric makes it relatively easy to "pass" with a 0.5, and quite difficult to "ace" the question and score 1.0. A score of 0.5 would count as a "pass" in both the LongMem and LoCoMo judge systems. This property gives BEAM scores a much higher ceiling of excellence, and testing Honcho with BEAM has given insight into how we can improve our system beyond just 'perfect recall.'
Honcho produces state-of-the-art scores according to the judgment framework proposed by the paper. On the smallest test, BEAM 100K, we observe a baseline score of 0.53 from Claude Haiku 4.5, and a Honcho score of 0.63. Since Haiku only has a context window of 200,000 tokens, the baseline scores stop there. But Honcho continues:
| BEAM | Top Score in Paper | Honcho Score | Dreaming | Batching |
|---|---|---|---|---|
| 100K | 0.358 | 0.630 | ON | 8,192 |
| 500K | 0.359 | 0.649 | OFF | 4,096 |
| 1M | 0.336 | 0.631 | OFF | 4,096 |
| 10M | 0.266 | 0.406 | OFF | 4,096 |
Notably, there's no drop-off in recall performance until 10 million tokens (though it likely begins after a few million).
Reflection
Some patterns emerge across all benchmarks. Questions that simply require recall of an entity's preference or a biographical fact about them are easy: Honcho pretty much aces these, and baseline tests fare well too. Across single-session-user and single-session-assistant questions in LongMem, for example, we pass 95%. We score 0.95--nearly perfect--on BEAM 500K's preference-following section.
Questions that ask about temporal reasoning are trickier: 88.7% in LongMem, 77% in LoCoMo, 0.49 in BEAM 500K. Frustratingly, these are some of the most common types of questions that a user comes across when subjectively evaluating an agent's memory. While Honcho significantly improves an LLM's ability to deal with questions about time, this is a genuine weak point of all models available today. It's part of what leads many users to continually underestimate the intellect of various models. Many models, when asked, will refuse to believe the current date if told, instead insisting that their training cutoff defines the current moment. We'll continue to research this flaw and apply best-in-class solutions.
No benchmark is perfect. Across all three, we've noticed a scattering of questions that are either outright incorrect or trigger high variance in models. These are especially prevalent in temporal reasoning questions: if a user has a discussion with an assistant in 2025, about having first met their spouse in 2018, and having been together for five years, there's meaningful ambiguity about how long the user knew their spouse before dating. Ambiguity arises both in measurements of time (when in 2018 did they meet?) and semantics (did they start dating when they first met, and have been married for five years, or did they meet and then actually start dating two years later?). Each benchmark has dozens of questions with ambiguous answers, with at least a couple outright wrong answers. These are the perils of synthetic data.
We also find that the best answer for a benchmark does not always align with the best answer for an interactive tool. Like a multiple-choice test, benchmarks reward confidently guessing and moving on if the answer is unclear. In the real world, we'd prefer Honcho to interact with the user or agent and prompt them to clarify what they meant, and we've stuck to this behavior even in the configurations of Honcho that we run benchmarks on.
3. Benchmarking Cost Efficiency
Honcho demonstrates excellent cost efficiency and can be used to significantly reduce the cost of using expensive LLMs in production applications.
The cost savings from using Honcho scale with 2 primary factors: (1) the amount of content ingested and (2) the number of queries made against the content. With a sufficient amount of data (about 100,000 tokens), savings occur after just a single question. Conversely, if only reasoning over a few thousand tokens, Honcho never confers cost savings and most use cases with such minimal context needs would be better served by just populating the context window directly.
Note: these cost calculations use the open-source Honcho software--Honcho is also offered as a managed SaaS service that passes most savings directly to the user, and employs powerful fine-tuned models for even better performance.
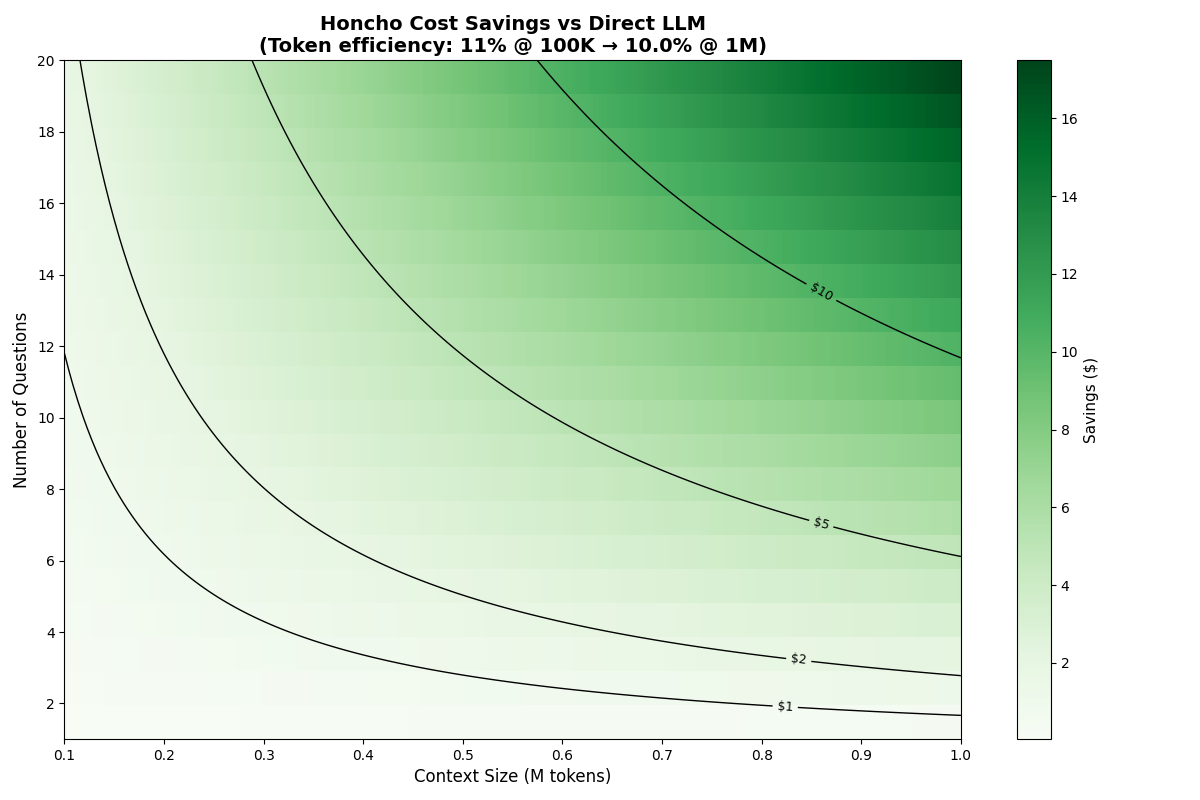
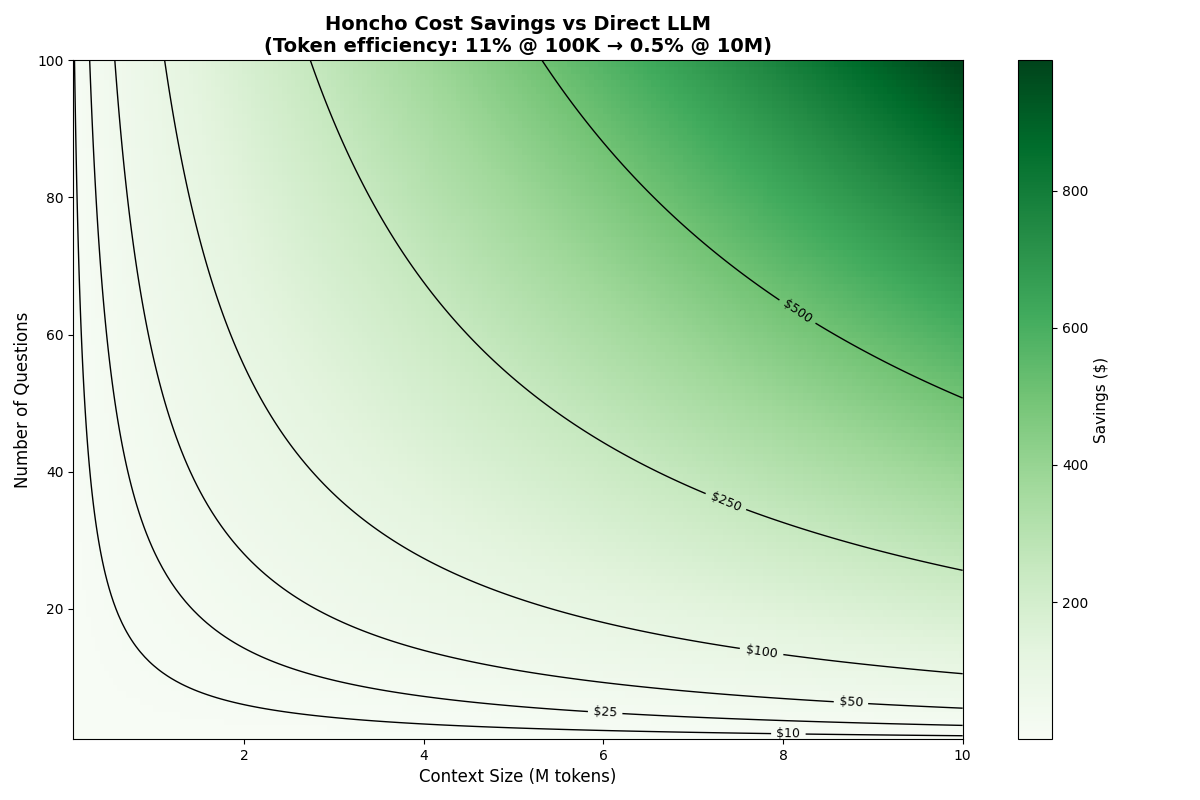
(In the above charts, comparisons are made using Claude Haiku 4.5 in Honcho vs. directly. We've also created a calculator that generates the same data with several models on our eval page)
Token efficiency here refers to the number of tokens used in various memory benchmarks to answer a question divided by the total context available for that question. A lower number is therefore better.
Empirically we observe that below about 50,000 tokens, Honcho's efficiency can approach or even exceed 100%, meaning that the chat endpoint agent uses as many or more tokens to answer the question as are available in the base data set. This is due to prompt and tool-calling overhead plus the fact that more complex questions and data prompt the agent to attempt to be exhaustive in its search for the truth. As the data set grows, though, efficiency scales rapidly. We observe that Honcho has an average 11% efficiency during the LongMem benchmark, meaning it uses on average only ~12,650 of the ~115,000 available tokens to answer each question. Token efficiency continues to improve over massive scales, with Honcho averaging 0.5% efficiency during BEAM 10M.
Notably, these calculations scale with more expensive models. Haiku token input is fairly cheap at $1 per million tokens. A more expensive model means Honcho confers savings even faster.
Example Scenarios
#1
Over the course of just a few days, a user chatting regularly with an AI assistant can produce 250,000+ tokens of message history. Sharing this history with a powerful research model like GPT-5-Pro would cost $3.75 for a single question. Using Honcho, both ingesting this context and querying it once would cost only ~$0.15. If an expensive model is necessary to complete a task, it would be foolish not to expose Honcho's chat endpoint to it as a tool, allowing the expensive model to provide its superior reasoning across only the relevant context. Repeated queries across a long message history with Honcho will rapidly save hundreds of dollars for a single user.
#2
A matchmaking system with thousands of users wants to use Claude Opus 4.5 to create high-quality "date me" docs for each user who has volunteered their email inbox as source material to extract their lifestyle and preference data. Rather than having Opus churn through 10M+ tokens per inbox, costing $50+ per user, use Honcho to ingest the data and perform a dozen targeted chat queries: using the same configuration as the BEAM 10M benchmark run above, this would cost about $6.
Conclusion
We're glad to hit state-of-the-art numbers--they validate that our architecture works--but scores on LongMem or LoCoMo are not the final goal. And it turns out that these benchmarks are starting to lead people astray from what agent memory really means.
Other memory systems, focused only on recall, are beginning to underperform baseline with the latest models on small-context tests. The good news, for us and for agent builders, is that we're only interested in recall as a step towards true stateful simulation, powered by identity modeling, powered by continual learning. Getting agents to correctly model users and other agents (and eventually experiences, tasks, etc) is far more of a roadblock to production-ready agents than simple recall.
The goal is to build systems that form perfect representations of identity7 via logical reasoning over social information, not systems that can regurgitate facts from conversation history. We're looking for answers to questions like: What does this person want? What do they think about? What would surprise them? Who are they? Benchmarks don't test for that.
BEAM 10M proves Honcho can reason over token counts that exceed any model's context window. That unlocks use cases that were previously impossible: agents with years of continuous memory, products that actually know their users, AI that improves its model of you faster than you update your model of yourself. We'll keep publishing benchmark results as we improve, but we'd rather you judge Honcho by what it enables you to build. Try the managed service, dig into the open source, and let us know what works and what doesn't.
Footnotes
-
Honcho forms a
Representationof eachPeerwho writes messages. ↩ -
Dreams are background tasks, managed by agents, that serve several purposes within Honcho: they prune excess information, consolidate duplicated information, create deductions and further reasoning, and much more. ↩
-
A theme throughout these benchmarks is the use of an LLM judge. All scores must be considered with variance in mind: not only is the model answering the question non-deterministic, so too is the judge model (yes, the judge prompt is run at temperature 0, but no, this does not equal determinism, plus, minute differences in the wording the answer being judged can trigger large changes even at temperature 0). These non-deterministic data sources combine to form fairly high variance. ↩
-
In some cases the answer provided in the benchmark is arguably wrong. See the issues section of the LongMem GitHub repo. ↩
-
Hindsight claims a score of 91.4% on LongMem S, but that score is achieved using Gemini 3 Pro, which scores 92% when run directly against the same test. The full code to reproduce this finding with Gemini 3 Pro can be found here--just set MODEL_BEING_TESTED and bring your own API keys. ↩
-
The LoCoMo paper proposes a token-based F1 scoring methodology, but we use LLM-as-judge, in line with other memory frameworks and our prior research. ↩
-
Really a Honcho peer can be any entity (human, agent, NPC, group, brand, task, experience, concept) that remains the same yet changes from time t to t+1,... ↩