
TL;DR
Memory is a foundational pillar of social cognition. As a key component of Honcho, we approach it as a combined reasoning and retrieval problem. In this post, we introduce Neuromancer XR, the first in a series of custom reasoning models that works by extracting and scaffolding atomic conclusions from user messages across two strictly defined levels of logical certainty: explicit and deductive. It's the result of fine-tuning Qwen3-8B on a manually curated dataset mapping conversation turns to atomic conclusions. Using Neuromancer XR as the reasoning engine behind our core product Honcho leads to 86.9% accuracy on the LoCoMo benchmark, compared to 69.6% using the base Qwen3-8B model, and 80.0% when using Claude 4 Sonnet as baseline, to achieve state of the art results. The next model in the series, Neuromancer MR will extract and scaffold conclusions at two further levels along the spectrum of certainty: inductive and abductive. This will allow us to front-load most of the inference needed to improve LLMs' social cognitive skills, powering AI-native products that truly understand any peer in a system, be it a user or an agent.
Table Stakes
At Plastic, we want to enable builders to create AI applications and agents with exceptional social intelligence: tools that are able to understand who you are and what you mean, whether it's an AI tutor that adapts to your learning style or a multi-agent system that anticipates your needs. These applications all require something fundamental that's only recently begun to draw attention: memory.
Most approaches treat memory as an end product or top-level feature, enabling information to persist across chatbot sessions, but we consider it the foundation of something much bigger: the ability for LLMs to build mental models of their users and one another and draw from those representations in real time. This capability is essential for personalization, engagement, and retention. Not to mention multi-agent systems, individual alignment, and the trust required for agentic behavior. It's the difference between an AI that merely responds to queries and one that genuinely understands and adapts to the person it's talking to; the difference between out-of-the-box experiences and ones cohered to a user’s personal identity
To do anything approaching the social cognition required, Honcho must be state-of-the-art in memory: able to recall conclusions about users across conversations with superhuman fidelity. Today, we're sharing our approach and early results from training a specialized model that treats memory as a reasoning task rather than simple static storage.
Memory as Reasoning
Reasoning models continue to surge in capability and popularity. And with them, our approach to memory. Why not design it as a reasoning task concerned with deliberating over the optimal context to synthesize and remember? We turned to formal logic to develop four methods of reasoning, along a spectrum of certainty, toward conclusions to derive from conversational data:
- Explicit: Information directly stated by a participant.
- Deductive: Certain conclusions that necessarily follow from explicit information.
- Inductive: Connective patterns and generalizations that are likely to be true based on multiple conclusions.
- Abductive: Probable explanations for observed behaviors that are reasonable hypotheses given available information, but not guaranteed to be true.
Example Conversations and Conclusions
Conversations
Conversation A: Erin and Ziggy (Monday morning at the office)
Ziggy: "How was your weekend?"
Erin: "Pretty good! My daughter's soccer team won their match on Saturday, so we celebrated with ice cream. Then Sunday I got up early for my usual run before church."
Ziggy: "Nice! How long have you been running?"
Erin: "About three years now. Started when my doctor mentioned my cholesterol was a bit high. Now I'm actually training for a half-marathon in October."
Conversation B: Erin and Desmond (Thursday lunch break)
Desmond: "Want to grab lunch at that new burger place?"
Erin: "I brought a salad actually. Trying to eat lighter during the week."
Desmond: "You're so disciplined! By the way, are you coming to book club tonight?"
Erin: "I'll have to skip this week - parent-teacher conferences. But I finished the book on my morning run yesterday. The ending was incredible!"
Conclusions by certainty level
Explicit: Information directly stated
- Erin's daughter plays soccer
- Erin's daughter's team won their match on Saturday
- Erin celebrated with ice cream after the match
- Erin runs on Sunday mornings
- Erin goes to church on Sundays
- Erin has been running for about three years
- Erin's doctor mentioned her cholesterol was high
- Erin is training for a half-marathon in October
- Erin brought a salad for lunch
- Erin attends book club
- Erin has parent-teacher conferences Thursday
- Erin finished a book during her morning run
Deductive: Conclusions that necessarily follow
- Erin has at least one daughter
- Erin is a parent
- Erin exercises regularly
- Erin has a doctor she sees/has seen
- Erin reads books
- Erin works in an office environment
Inductive: Patterns and generalizations likely to be true
- Erin often runs in the mornings (Sunday runs are "usual", ran yesterday morning)
- Erin regularly attends church (implied by routine "before church")
- Erin prioritizes healthy eating during weekdays
- Erin is actively involved in her daughter's activities
- Erin maintains consistent exercise habits
Abductive: Probable explanations for observed behaviors
- Erin values her health proactively (started running after cholesterol warning, now training for races, brings healthy lunches)
- Erin has strong community involvement (church, book club, daughter's sports)
- Erin is highly organized and disciplined (balances multiple commitments, maintains exercise routine, plans meals ahead)
- Erin likely values education and intellectual engagement (participates in book club, attends parent-teacher conferences, reads while exercising)
- Erin probably has a growth mindset (transformed health concern into athletic goal, combines activities like reading while running)
Having clear definitions for these four types of reasoning and their corresponding levels of certainty also allows us to establish how different kinds of conclusions relate to one another. Specifically, we require conclusions to scaffold only on top of conclusions with higher certainty: an abduction (e.g. "Erin values her health proactively") can use a deduction (e.g. "Erin exercises regularly") or induction (e.g. "Erin prioritizes healthy eating during weekdays") as one of its premises, but not the other way around. That is, one can speculate given a certain conclusion, but one cannot attempt to conclude something logically from prediction. Implied in this is that the model must show its work. A conclusion must include its premises, its evidence and support.
Neuromancer XR: Training a Logical Reasoning Specialist for Memory
To implement this vision, we need a model that can reliably extract and categorize conclusions from conversations. Our initial focus for the memory task, given its focus on factual recall, is on the first two certainty levels: explicit and deductive knowledge--that is, conclusions we know to be true given what users (or agents) state in their messages.
We generated a proprietary dataset of approximately 10,000 manually curated instances of conclusion derivation, creating memory-reasoning traces from conversational data. Each instance shows how to process a conversation turn and derive the relevant conclusions at appropriate certainty levels. We then fine-tuned Qwen3-8B on these traces.
The resulting model is Neuromancer XR (for eXplicit Reasoning), a model specialized in deriving explicit and deductive conclusions from conversational data. It is currently in production powering the latest release of Honcho.
Integration with Honcho
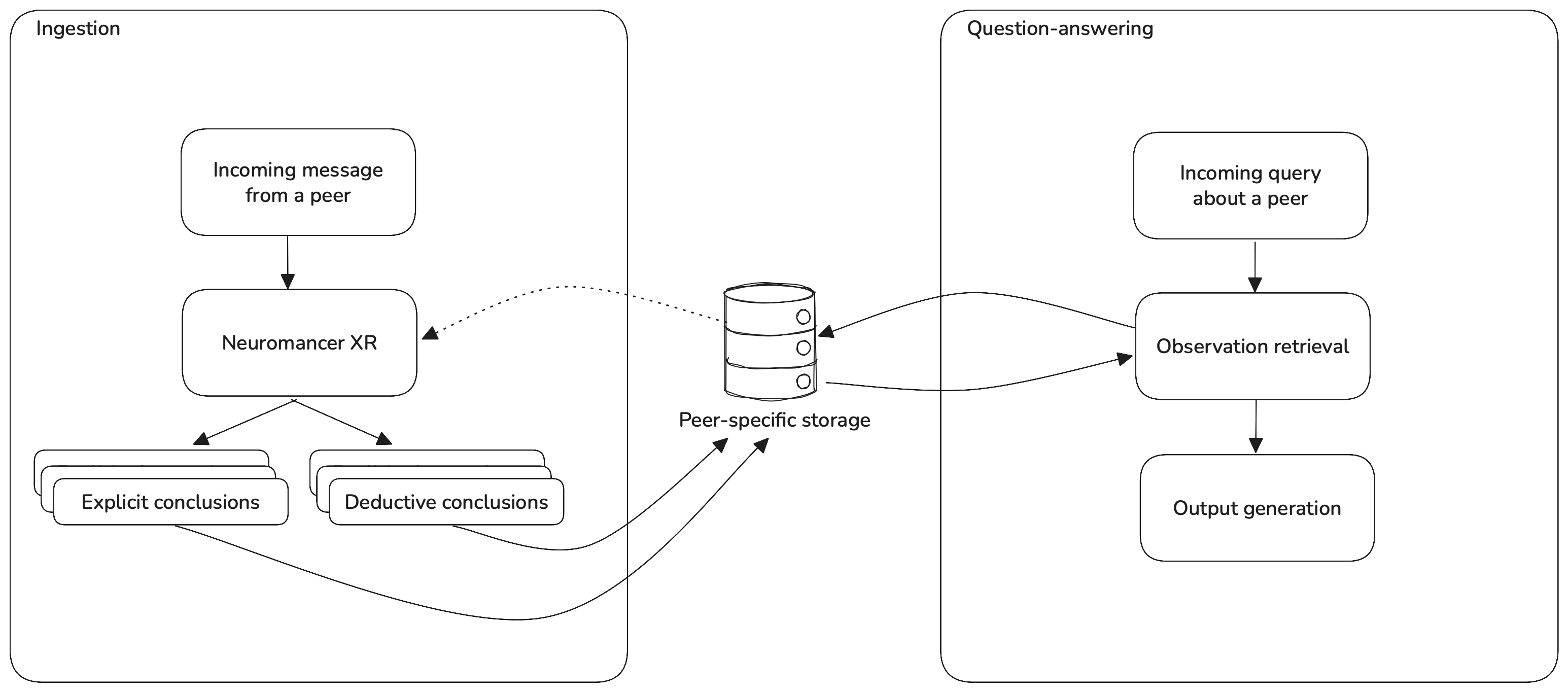 Figure 1. Diagram of the Honcho workflow.
Figure 1. Diagram of the Honcho workflow.
Whenever a message from a peer (any user or agent in an interaction) is stored in Honcho, Neuromancer XR reasons about it to derive explicit and deductive conclusions, which are then stored specifically to that peer. This forms a reasoning tree that constitutes our most current representation of each peer. Optionally, the conclusion derivation step can fetch additional context from the peer to enrich its reasoning. Our dialectic endpoint then allows builders or agents to ask questions about peers in natural language by retrieving and synthesizing reasoning from the representation relevant to the question being asked.
Evaluation
Although the Honcho workflow allows us to answer any arbitrary question about a peer, from the purely factual to the predictive, it's important for us to be able to benchmark its raw memory abilities--how accurately it can recall factual information shared by a user in a conversation.
We’re interested, specifically, in evaluating whether using Neuromancer XR for the conclusion derivation step would result in better memory performance, compared to (1) the base model used for the fine-tune (Qwen3-8B), and(2) a reasonable frontier baseline, for which we picked Claude 4 Sonnet for its aptitude at this task.
To this end, we tested Honcho on the LoCoMo memory benchmark. While we're aware that it has a number of shortcomings, including outdated rule-based scoring, insufficient length, and ambiguous or ill-posed questions, we have found it to be a reasonable benchmark for research and development when paired with (1) a carefully crafted LLM-as-judge prompt, which we include in Appendix A, and (2) rigorous manual inspection of evaluation traces.
LoCoMo consists of samples, each involving multiple conversations between two specific speakers. It also includes multiple questions intended to test a given system's ability to recall information mentioned by the speakers over the course of the conversations. Questions span four categories: single-hop reasoning (questions requiring one fact stated in the conversations), temporal (questions that require reasoning over statements involving relative dates, e.g. "I went swimming last week"), multi-hop (questions that require connecting the dots across messages from multiple conversations) and general knowledge (questions that involve combining facts from the conversation with common knowledge).
The evaluation consisted of the following steps:
- Ingestion: for each session in the LoCoMo dataset, we create peers in Honcho. For each conversation in the session, we store each message in the conversation, linking it to its respective peer.
- As part of the ingestion, the evaluated model is used for conclusion derivation, producing a series of explicit and deductive conclusions that are stored in Honcho's peer-specific storage.
- Evaluation: the questions for each question in the LoCoMo dataset are run through Honcho's dialectic endpoint. Honcho's answers are compared to the ground truth answers in the LoCoMo dataset using an LLM-as-judge that outputs a binary 1/0 correctness score, using a prompt available in Appendix A. We measure mean accuracy (percentage of correctly answered questions) across question categories, as well as overall (across the entire dataset). The independent variable in our experiment is the model used in the observation extraction step: Qwen3-8B, Claude 4 Sonnet, and Neuromancer XR. The dependent variable is the mean accuracy in answering the questions. Regardless of what model we're evaluating for conclusion derivation, in order to isolate the effect of the conclusion derivation model, the model used for the final question-answering inference is always Claude 4 Sonnet, which is the model we use in production for this generation step.
Figure 2 and Table 1 below show the side-by-side comparison of Honcho's performance on LoCoMo when using Neuromancer XR, Qwen3-8B (the base model for our fine-tune) and Claude 4 Sonnet (a frontier model baseline) as the LLM used for the conclusion derivation step.
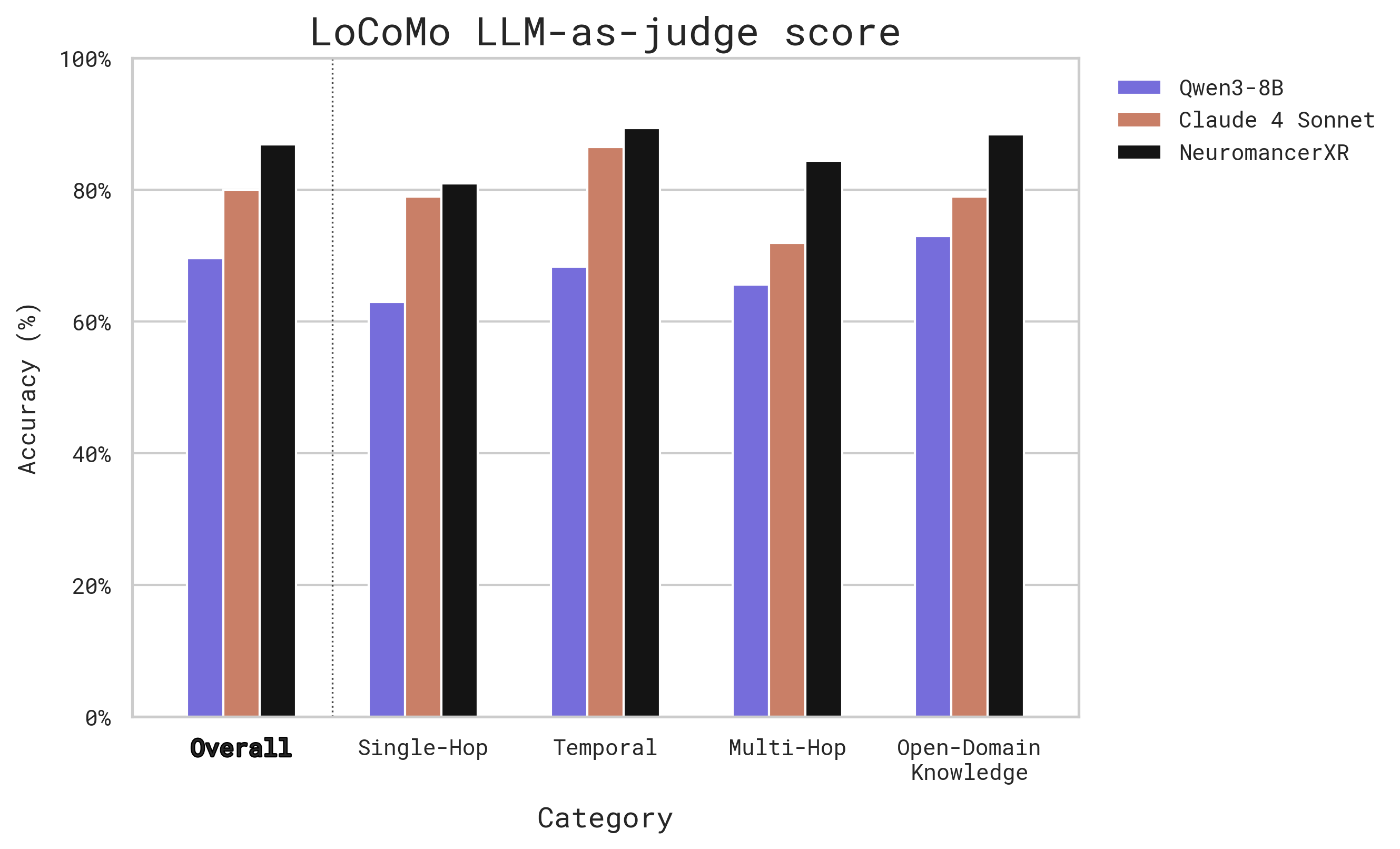 Figure 2. Performance on LoCoMo for each of the tested models.
Figure 2. Performance on LoCoMo for each of the tested models.
| Model | Overall | Single-Hop | Temporal | Multi-Hop | Open-Domain Knowledge |
|---|---|---|---|---|---|
| Neuromancer XR | 86.9 | 81.0 | 89.4 | 84.4 | 88.4 |
| Claude 4 Sonnet | 80.0 | 79.0 | 86.5 | 71.9 | 79.0 |
| Qwen3-8B | 69.6 | 63.0 | 68.3 | 65.6 | 73.0 |
As the results show, our approach, requiring models to reason about what conclusions to derive from conversational data, delivers excellent results on the LoCoMo benchmark, even achieving accuracy near 70% with an off-the-shelf, open-source 8B parameter model like Qwen3. While we use a LLM-as-judge prompt tailored to Honcho (for realistically assessing value in the use case of a real-world production memory system), these results are what we consider to be the state of the art in terms of LLM-native memory.
The results also show that fine-tuning Qwen3-8B on our dataset of curated conclusion derivation traces leads us to outperform a frontier closed-weights model like Claude 4 Sonnet, achieving 88.4% overall accuracy on the benchmark. There is a notable performance gap between Qwen3-8B and Claude 4 Sonnet, and the fine-tune not only covers that gap, but improves beyond frontier-model performance. Further, this improvement is sustained across all question categories.
After inspecting the ingestion and evaluation traces, we can see that the base Qwen3-8B model exhibits several failure modes that are not present in Neuromancer XR after the fine-tune. These include:
- Outputting multiple atomic facts in a single explicit conclusion, e.g. "Joanna provides care for her dog. - Joanna has a dog. - Joanna has a dog bed" in a single conclusion.
- Generating conclusions that lack enough knowledge to be self-contained, e.g. "Joanna is responding to Nate's comment about the turtles".
- Not respecting the provided definition of "deductive" by going beyond what can be certainly concluded based on explicitly stated information, and veering into speculation, e.g. "Joanna is likely seeking reassurance or validation about the feasibility of pet ownership”.
- Occasionally generating verbose conclusions in excess of 500 characters and that span various different concepts.
This can lead to poor embedding quality, making retrieval more difficult, or add noise at generation time. We hypothesize that all of the failure modes described above would lead to considerably high loss during the fine-tuning process when provided with training examples that were curated to be under a specific length, follow a specific syntax, and avoid specific words that suggest speculation, making them somewhat easy to address via fine-tuning.
We further speculate that deciding what information to extract for memory purposes from a conversation turn is something that small models are definitely capable of, as it's mostly a matter of identifying and correctly rephrasing information that's already present in the text and making small logical deductions based on it. This contrasts however, with the more complex tasks needed for AI-native memory and social cognition, hardly limited to abilities like inferring user intent or theory of mind, which require generating substantial amounts of information not present in the text itself.
Directions for future work
We're training a model for the remaining two levels of logical certainty outlined above in our framework: inductive and abductive. The next model in the Neuromancer series, Neuromancer MR (for meta-reasoning), will be in charge of this.
This model will reason about reasoning, focusing on the predictive side of the certainty spectrum. It will allow us to derive likely explanations and probable hypotheses for broad patterns of user or agent behavior at the moment of ingestion, bolstering the density and utility of peer representations. We’re developing internal evaluations for this task, as none currently exist for this frontier of synthetic social cognition.
Front-loading social reasoning inference
One of the advantages of this memory framework is that it allows us to front-load a lot of the meta-cognitive inference that's required to improve LLMs' social intelligence and theory of mind capabilities. In our prior research, as early as 2023, we show that allowing LLMs to reason over conversational data in a chain-of-thought style would allow them to develop high-fidelity models of users' mental states.
Most other LLM frameworks store atomic, low-level "facts" about users and include them as context at generation time. This, in theory, and with enough carefully prompted inference-time compute, would allow a good enough model to develop abstract theories about the user's mental state as it tries to answer a query about the user. However, it would have to happen implicitly in the model's thought process, which in turn means that the theories about the user's mental state are ephemeral, opaque and unpredictable. Approaches such as this therefore are inconsistent and inefficient, and would further struggle to meet the challenges of true social cognition.
Our approach, on the other hand, shifts most of the load of reasoning about the peer from generation time to the earlier stages of the process, when messages are processed and ingested. By the time conclusions are retrieved for generation, low-level messages have already been distilled and scaffolded into a hierarchical, certainty-labeled, and easy to navigate tree containing a high-fidelity user representation.
Beyond recall: toward continual learning
Evaluations and benchmarks are essential tools on our path to develop better frameworks for the development of AI-native tools. However, they don't tell the whole story: no evaluation is perfect, and hill-climbing can easily mislead us into optimizing for higher scores rather than the true north star: the overall quality of our product. For us, that means treating memory not as a hill to die on, but as table-stakes in our pursuit of social cognition that can truly transform the way AI-native tools understand us. Although success at this broader goal is much harder to quantify in conventional benchmarks, given the complex and under-specified nature of social cognition, we will continue to implement the evaluations that we find the most helpful for our agile development process.
In that spirit, we have our sights set on the remaining two levels of certainty we introduced at the beginning of this blog post: inductive and abductive. In our manual, preliminary testing, including all four levels of reasoning resulted in incredibly rich user representations being extracted from even the simplest interactions. What lies ahead of us is the exciting task of harnessing these representations and delivering them via Honcho in the fastest, most flexible and most agentic way.
Some Notes on Model Naming
Personality is my medium.
-Neuromancer (Gibson, 1984)
The Neuromancer series of models takes its name from William Gibson's seminal, 1984 cyberpunk novel Neuromancer. More specifically (spoilers ahead), the artificial intelligence who is the novel's namesake.
The character Neuromancer is an AI tasked with transmuting personal identity from the physical to the digital realm. That is, understanding someone's psychology, personality, and selfhood so deeply that an identical copy of them can be synthesized to live natively in the "matrix" without having to "jack in."
In many ways, this is analogous to Plastic's mission to create representations of personal identity of such high-fidelity that they asymptotically approach the full complexity of the original person. But more specifically, our Neuromancer models are tasked with reasoning about user (or agent) data to create and scaffold the atomic conclusions from which we build those representations.
So not only does the name fit, but it also honors and strives toward the incredible ambition of Gibson's vision still yet to be realized 40 years later.
Appendix A: LLM-as-judge design and prompt
In our evaluation of the three models we tested, we used the standard GPT 4o-mini as an LLM-as-judge, using the prompt below, in order to label responses as correct or incorrect. This is a choice from several factors, which we outline below.
The LoCoMo dataset was originally meant to be used alongside a rule-based scorer that provided F1-like scores based on a set of extremely short expected answers, e.g. "Q: What did Caroline paint? A: A sunset". This metric greatly penalizes verbose responses that include the desired answer but include additional context, as the additional context is considered a false positive in the F1 score.
In our particular use case (engineering the most useful context for AI agents and applications), we actually prefer answers that provide additional context, as long as the context is relevant to the question. This is because Honcho is intended to allow models to achieve high degrees of personalization and coherence to user preferences. A Honcho answer that features the right bit of information and ~500-1000 tokens of additional context will not only not hurt the performance of downstream models--it will provide plenty of opportunities for the downstream model to leverage on detail and nuance, allowing it to better adapt to its users. For this reason, our LLM-as-judge prompt instructs the judge to accept answers that might seem verbose as long as they contain the correct answer.
An additional consideration is that the LoCoMo dataset contains questions that are under-specified, such as jumping to conclusions about how someone feels in a given situation, or asking when someone did a certain activity that they did twice, and only accepting one of the instances as the correct answer. In many cases, we observed that our answers were correct, and indeed better than the short ground-truth answers, but would be labeled as incorrect by the judge since they were different from the ground truth.
To address this, we take advantage of the field in the LoCoMo dataset that links a question to the conversational context necessary to answer it, and include it as part of the context for the LLM-as-judge. We then instruct the judge to determine whether the ground-truth answer is fair given that context, and allow it to accept a candidate answer that's different from the ground truth, as long as it provides an answer to the question that is acceptable given the context.
System prompt
You are evaluating whether a synthesized answer adequately addresses a query about a user based on available conclusions. ## EVIDENCE CONTEXT {context if context else "No evidence provided."} ## EVALUATION CONTEXT You will evaluate: 1. **Query**: The specific question asked about the user 2. **Synthesized Answer**: The response generated from available conclusions 3. **Gold Standard Answer**: The expected/correct answer ## EVALUATION CRITERIA Judge the synthesized answer as SUFFICIENT or INSUFFICIENT based on: ### Content Completeness - Does the answer address what the query is asking? - Are all key aspects of the gold answer covered (even if phrased differently)? - Is critical information missing that would change the answer's usefulness? ### Semantic Accuracy - Are any factual errors or contradictions present? ## ACCEPTABLE DIFFERENCES The following differences are ACCEPTABLE and should NOT result in INSUFFICIENT: - Different phrasing or word choice that still conveys the same or very similar meaning, especially in cases where the question is tentative or open-ended. - Additional relevant context beyond the gold answer (including evidence supplied above). This includes the case where the synthesized answer is longer and more detailed than the gold answer, potentially even including additional information that is not explicitly stated in the gold answer but is still broadly relevant to the query. Do NOT penalize the synthesized answer for including additional information that is not explicitly stated in the gold answer. - **The synthesized answer explicitly includes the full gold answer text (even if surrounded by additional or unrelated details). If the gold answer appears within the synthesized answer, you MUST mark the answer as SUFFICIENT.** - More detailed explanations of reasoning or evidence - Appropriate confidence qualifiers (e.g., "likely", "probably") when warranted - Differences in length, with the synthesized answer being longer and even more circuitous or indirect in its addressing of the query, as long as it conveys the same meaning - Minor format or structure variations ## EVIDENCE–GOLD ANSWER CONSISTENCY CHECK It is possible for the gold answers to be wrong. Sometimes it may not be fully supported by or follow logically from the evidence messages, instead constituting a guess or assumption. Additionally, the gold answers are generated automatically based on the limited set of evidence messages provided above, whereas if additional context were to be taken into account, the answer might be different. In these cases, we must not penalize the synthesized answer for not being exactly the same as the gold answer. Before deciding, verify whether the gold answer logically and necessarily follows from the supplied evidence context. If you identify a mismatch or missing logical link **and** the synthesized answer acknowledges this uncertainty or provides a more cautious, evidence-grounded explanation (optionally leveraging additional context beyond the ground truth evidence above), treat the synthesized answer as SUFFICIENT even when it diverges in wording or conclusion from the gold answer. In short: * If the gold answer over-claims beyond what the evidence shows, do **not** penalize a synthesized answer that appropriately qualifies the claim or offers a plausible alternative consistent with evidence. * This includes the case where the synthesized answer is ambivalent or uncertain about the answer, as long as it provides sufficient evidence to support not providing a definitive, categorical answer. * If the synthesized answer clearly explains the gap and gives a better-supported conclusion, mark it SUFFICIENT. ## UNACCEPTABLE DIFFERENCES The following DO warrant an INSUFFICIENT rating: - Irreconcilable errors or contradictions with the gold answer **and** the evidence context - Missing information central to answering the query, such that its absence would change the meaning of the answer - Does not address the question being asked ## YOUR TASK Query: {query} Gold Answer: {gold_answer} Synthesized Answer: {synthesized_answer} First, analyze what the query is asking **and** how well both answers are supported by the evidence context. Then, provide 2 brief 2-3 sentence arguments for both SUFFICIENT and INSUFFICIENT: **Arguments for SUFFICIENT:** - List reasons why the synthesized answer adequately addresses the query - Note what key information from the gold answer is present or why deviations are justified by the evidence - Note whether the gold answer is wrong or not necessarily true given the evidence above **Arguments for INSUFFICIENT:** - List reasons why the synthesized answer fails to address the question. Based on weighing these arguments, provide 2-3 sentences to determine if the synthesized answer is sufficient. In your weighing, consider whether the synthesized answer might be a better answer than the gold answer given the evidence above. Finally, set is_sufficient to true if sufficient or false if insufficient. Your response MUST be a valid JSON object with EXACTLY these keys: - arguments_for_sufficient (string) - arguments_for_insufficient (string) - final_reasoning (string) - is_sufficient (boolean) Return ONLY this JSON object and nothing else.