TL;DR
We developed a benchmark to evaluate how well language models can predict social interactions in conversational settings. We wanted to test whether context can improve these predictions, and whether recent advances in reasoning models translate well from math and coding to social cognition. By testing various models on the task of predicting the next message in real Discord conversations, with and without different types of context, we found that Claude 3.7 Sonnet significantly outperforms other models in its non-reasoning variant, while its reasoning variant performed between 10 and 15 percentage points worse. We discovered that generating context summaries with a smaller model (Llama 3.3 70B) and injecting these into inference yields comparable or better results than providing raw conversation history. On one hand, we're excited that this validates key aspects of the thesis behind our product Honcho. On the other hand, we discovered that models highly optimized for technical reasoning often underperform on social cognition tasks.
Check out the code here.
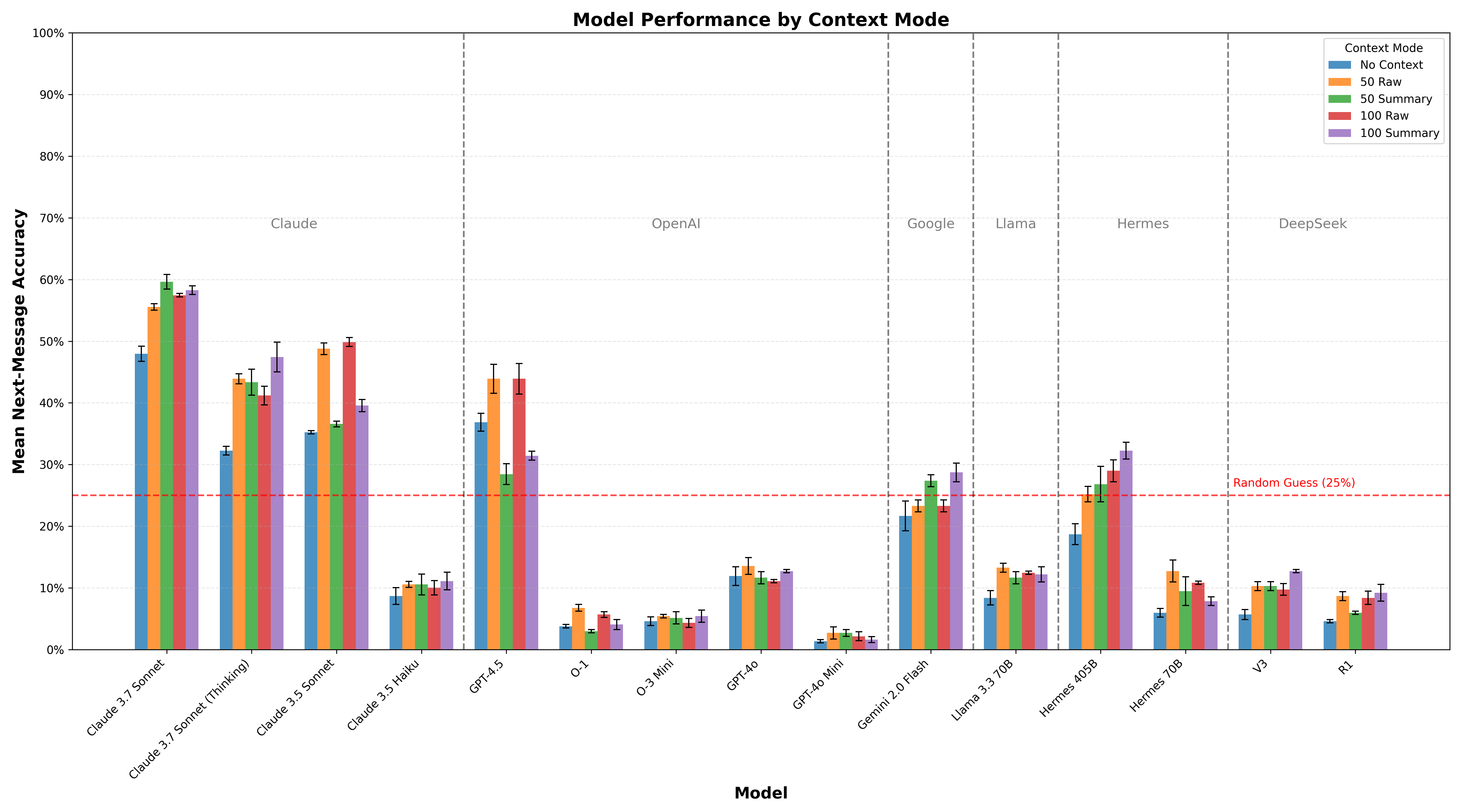
Figure 1. Next-message prediction accuracy (%) by model and context mode. Error bars show standard error over three different runs with different random seeds to shuffle the order of the options.
Finding Verifiable Social Rewards
The machine learning community has made significant progress optimizing language models for tasks with clear, verifiable answers, like math, coding, and factual reasoning. These domains offer what are called "verifiable rewards": objective measures that can be used for reinforcement learning without relying on human preferences or subjective judgments. While this approach has yielded impressive results for technical reasoning, at Plastic Labs we've become increasingly curious about whether similar verifiable reward structures could be developed for social intelligence.
Here, by social intelligence we mean the ability to accurately interpret others' intentions, emotions, and likely behaviors in social contexts--essentially modeling other minds to predict social outcomes. In this sense, our social cognition is as essential to our functioning as having a robust predictive model of physics, our environment and proprioception. While humans develop this ability naturally through social feedback (successful predictions are "rewarded" with smoother interactions), creating objective measures for this in AI systems remains challenging.
To address this gap, we developed a multiple-choice next-message prediction task using real conversations from our team's Discord. The premise is straightforward: given a snippet of conversation between two people and four possible options for what came next (with only one being the actual message), can a model identify the correct response?
This creates a clear, verifiable reward signal for social understanding: either the model correctly identifies the real message or it doesn't. Yet unlike many technical tasks, success requires the model to understand conversational dynamics, recognize individual communication patterns, track context across multiple turns, and model how different people behave in specific social contexts.
This benchmark also allows us to test whether models specifically optimized for technical reasoning generalize to social understanding, and to get a granular, quantifiable understanding of models' social reasoning abilities.
Prior work & inspiration
At Plastic Labs, our journey into AI social cognition began with our experimental tutor, Bloom. We discovered that giving AI systems autonomy to reason about the user's psychology led to dramatic improvements in performance. By allowing models to predict users' mental states and identify what additional information they needed, we found that AI systems could develop a nascent theory of mind for each user. This approach, which we later formalized in our research on metacognitive prompting, demonstrated that social context reasoning can significantly reduce prediction errors in large language models.
With recent work on reasoning models, including DeepSeek's R1, showing remarkable gains through reinforcement learning on mathematical and coding tasks, we're particularly interested in developing verifiable social rewards that could drive similar improvements in social reasoning. Unlike technical domains with clear right and wrong answers, social prediction introduces unique challenges--yet, establishing benchmarks in this area could unlock entirely new dimensions of AI capability that are crucial for creating systems that truly understand and adapt to human users.
Methodology
Dataset Creation
We created our dataset by extracting conversation snippets from our internal team Discord channels (accessible only to our core team of 5-10 people). Each snippet contained:
- 6-10 messages between exactly two participants.
- At least two messages from each participant, ensuring each person had at least two conversational turns.
- A target message (the message that was sent immediately after the snippet).
For each genuine target message, we generated three convincing decoys using Claude 3.7 Sonnet. These decoys were designed to be plausible alternatives that matched the style and substance of the real message while being distinctly different.
We specifically chose to use our internal Discord data because it represents authentic, messy communication—complete with inconsistent formatting, shorthand, emojis, and other real-world conversational artifacts that make this a particularly challenging test.
We ended up with 123 snippets—below is an example:
Context
- Vince: the ultimate test of trust
- Courtland: oh shit, like that could be the eval metric! you can directly monitor coherence over time by monitoring how your honcho wagers in a prediction market or how it interacts in a socal sandbox with other agents this is always running if you want and updating as it learns about you
- Vince: yeah, over-arching idea here is to come up with a plethora of ways to assess the coherence of the psychological renderings to their principals IRL
- Courtland: you could even "train" your honcho by reviewing and rewarding highly cohered actions
- Courtland: exactly, ones that are relevant in practice
Options
Next message from Vince:
- A) I'm thinking we need to establish some baseline metrics first though - like what does 'coherence' even mean in this context? psychological fidelity?
- B) this reminds me of those old Tamagotchi pets, but instead of feeding it you're constantly training it to think like you do. kinda wild when you think about it
- C) yeah and we could even gamify the process, giving users points for when their honcho makes decisions that align with what they would've done
- D) ohh yeah like a more proactive approach as opposed to being bayesian, updating priors based on new information
Can you guess the right answer?
D! Classic Vince being Bayesian.
Context Modes
Upon visual inspection of the resulting dataset, we found that the decoys were remarkably similar to the real messages, making it difficult even for us to consistently identify the genuine response. We wondered if providing additional context about the users might help determine the correct answer, which led us to explore different context modes:
- No Context: Models only received the immediate conversation snippet and the four options.
- Raw Context: Models received the conversation snippet plus the previous 50 or 100 messages from the Discord history (unfiltered and unprocessed).
- Summary Context: Models received the conversation snippet plus a generated personality profile of the target user, created by processing the previous 50 or 100 messages through Llama 3.3 70B. The prompt used to generate this summary is available in the project repo on GitHub.
This design allowed us to compare whether any context provides useful signals for predicting social behavior, and whether a summary can provide results comparable to the full context.
Experimental Setup
We tested a wide range of models including:
- Claude 3.7 Sonnet, Claude 3.5 Sonnet, Claude 3.5 Haiku.
- GPT-4.5, GPT-4o, GPT-4o Mini, O-1, O-3 Mini.
- Google's Gemini 2.0 Flash.
- Meta's Llama 3.3 70B Instruct.
- Nous Research's Hermes 3 (405B and 70B variants).
- DeepSeek models (Chat and R1).
For each model and context mode combination, we ran three trials with different random seeds to control for position bias in option selection. Ideally we would have run more trials, but we wanted to constrain the compute needed for this experiment.
Results and Discussion
The results of our experiment are shown in Figure 1. In this section, we analyze them in detail and provide some insights and interpretation.
Figure 1. Mean next-message prediction accuracy (%) by model and context mode. Error bars show standard error over three different runs with different random seeds to shuffle the order of the options.
Context Helps Regardless of Form
Additional context helps models predict social behavior, whether that context is provided as raw conversation history or as a processed summary. Moving from no context to either raw or summary context yielded substantial improvements for virtually all models tested. This confirms what might seem intuitive: knowing more about someone helps predict what they might say next.
Efficient Context Processing Works
What's particularly significant is that injecting pre-processed summaries of user context works as well as or better than providing raw context for most models. This has important implications for system design:
- The summaries contain far fewer tokens than raw context (approximately one paragraph versus potentially thousands of tokens).
- The summarization can be done once with a smaller, cheaper model.
- The resulting performance gains are substantial compared to no-context baselines, and in some cases even better than providing the full context.
This supports a core thesis behind Honcho: ambient processing of user context to generate compressed representations can improve model performance while keeping inference costs manageable. Rather than injecting massive amounts of data into the context window, models can achieve better results with distilled personality profiles.
We didn't observe significant performance differences between 50-message and 100-message contexts, suggesting there may be diminishing returns beyond a certain point. This is likely dependent on factors like user count and conversation density.
Newest Models Lead the Way
Only the newest models perform well on this task. Claude 3.7 Sonnet and GPT-4.5 (both released last week) were the only models to achieve accuracy significantly above 40% in any context mode, with Claude 3.7 (non-thinking) reaching nearly 60% accuracy with summary context—more than doubling the 25% random baseline.
This is particularly interesting because tasks that would have seemed impossible for models that existed just months ago are now becoming tractable. This rapid progress also informs how we should think about designing evaluations—creating hard tasks that aren't saturated from the start rather than ones where models already perform at ceiling.
Different Models Benefit from Different Contexts
While summary context generally outperformed raw context, this pattern wasn't universal. Some models (notably Claude 3.5 Sonnet and GPT-4.5) performed better with raw context than with summaries. This suggests different architectures may vary in their ability to extract relevant information from different types of context.
Reasoning vs Social Understanding Trade-offs
The relatively poor performance of models optimized for technical reasoning, like Claude 3.7 Sonnet (thinking), DeepSeek R1, and OpenAI's O-1 and O-3 Mini, raises interesting questions. Despite their strong results on math and coding benchmarks, these models achieved well below random performance on our social prediction task.
This suggests potential trade-offs in model optimization. The reinforcement learning or supervised fine-tuning techniques used to enhance reasoning abilities might come at the expense of social cognition capabilities. However, without access to the architectures, data and training procedures that major labs like Anthropic and OpenAI use to build these models, it's hard to know exactly what might be causing models like Claude 3.7 Sonnet and GPT-4.5 to perform so much better on this task.
Caveat: Decoy Generation
We should note that our decoys were generated using Claude 3.7 Sonnet, which was also the best-performing model on the task. It's possible that Claude 3.7 is better at recognizing the subtleties in its own generations. However, this almost creates a generative adversarial setup—Claude 3.7 is both generating challenging decoys and trying to identify them—which makes its strong performance even more notable.
Future Directions
Verifiable Social Rewards for RL
So far, we've used this task purely as an evaluation metric, but with a large enough dataset, it could potentially serve as a reward signal for reinforcement learning. This would allow for optimization of social cognition abilities with objective metrics, similar to how technical reasoning has been enhanced. Expanding our toolkit of objective social evaluation metrics could help bridge the gap between technical and social intelligence.
Social-Reasoning Balance
Can we develop training techniques that enhance reasoning capabilities without sacrificing social cognition? This might involve carefully designed datasets that balance technical and social tasks, or novel fine-tuning approaches that preserve multiple types of capabilities. Understanding the apparent trade-off between these abilities could be crucial for developing more well-rounded AI systems.
Context Optimization and Alternative Approaches
We're also interested in exploring several technical improvements to the methodology: finding the minimum effective context window size across different environments; testing different prompting techniques and models for generating personality summaries; experimenting with combinations of raw and summary contexts; and trying different models for decoy generation to address potential advantages Claude 3.7 might have in recognizing its own outputs.
Conclusion
We were excited to find that this social prediction task was genuinely challenging for most current models, with only the very latest releases showing strong performance. The fact that models optimized for reasoning performed poorly suggests interesting trade-offs in current training approaches. Meanwhile, the effectiveness of pre-processed context summaries supports a key principle behind Honcho: ambient processing of user context can significantly improve personalization while managing compute costs.
Check out the code here. We used our private Discord messages for the experiment so we're unable to publish our own dataset, but the repository contains instructions to replicate the experiment with your own data. If you have any questions, feel free to ask on GitHub!
If you're interested in discussing this research or exploring how improved social modeling could benefit your AI applications, join our Discord or reach out to us at hello@plasticlabs.ai.